

Connecting dbt™ Pipelines to BigQuery
Combining dbt™ with Google BigQuery can significantly enhance data workflows.

Emelie Holgersson
Aug 8, 2024
·
1
min read

Google BigQuery is a fully managed, serverless data warehouse designed for large-scale data analytics. It leverages SQL queries and a massively parallel processing (MPP) architecture to enable rapid querying of petabyte-scale datasets.
Key features include real-time data analysis, built-in machine learning capabilities, and seamless integration with Google Cloud services. BigQuery's pay-as-you-go model and automatic scaling enhance cost efficiency and performance
For teams focused on analytics engineering, combining dbt™ (data build tool) with Google BigQuery can significantly enhance data workflows. This quick guide explores how to effectively connect the two, enabling analytics engineers to leverage the strengths of both tools.
Setting Up Your dbt™ - BigQuery Connection
To run dbt™ pipelines with BigQuery, you need to configure your profiles.yml file. This crucial step manages connection settings and can be approached in two primary ways:
Service Account Key Authentication
OAuth Authentication
Service Account Key Authentication
This method uses a JSON key file for authentication, a common choice for data teams:
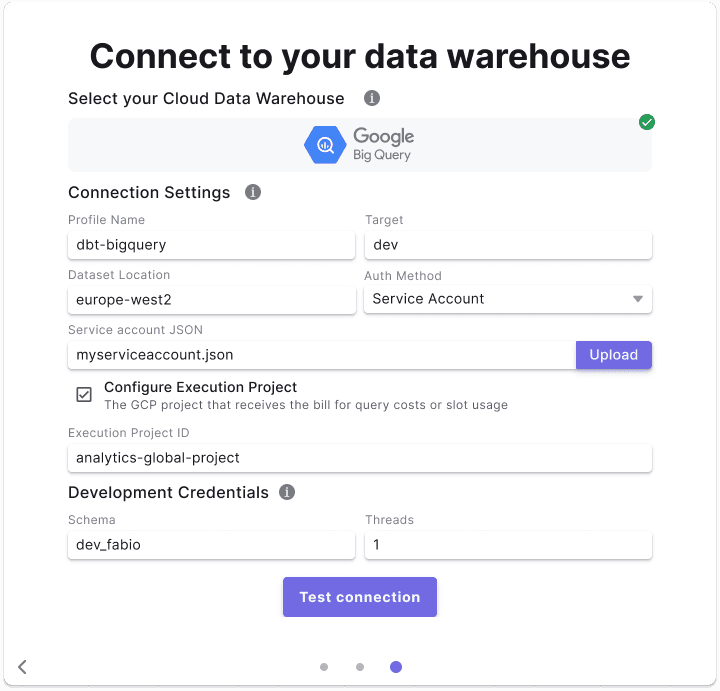
OAuth Authentication
For a more interactive approach favored by some analytics engineers:
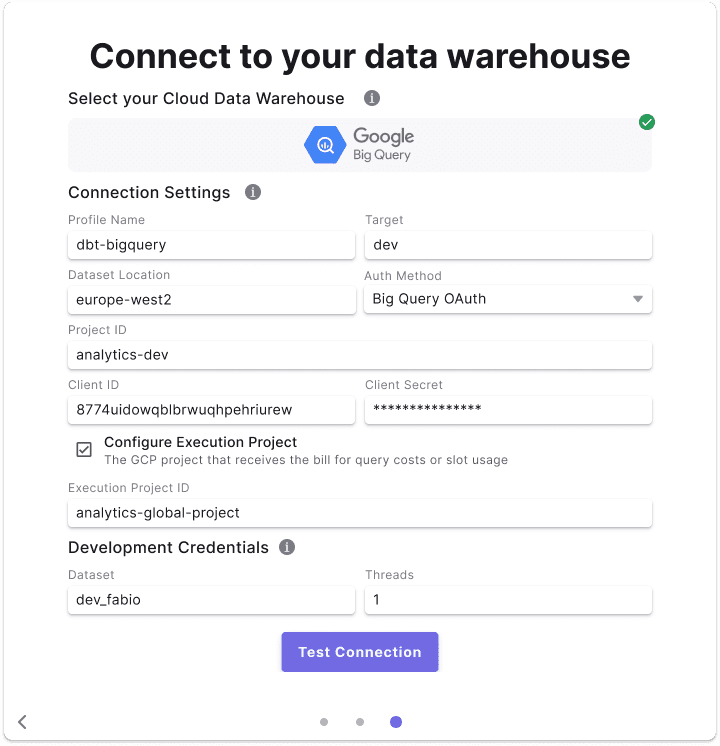
Once connected, you should consider these best practices:
Leverage BigQuery's columnar storage for efficient querying
Use dbt™ incremental models for large datasets to reduce processing time and costs
Implement appropriate partitioning and clustering in BigQuery tables for improved query performance
Learn more about BigQuery Connection in Paradime HERE.
Security Considerations for Data Teams
When setting up your dbt™ - BigQuery connection, follow these security guidelines:
Store sensitive information like keyfiles securely
Use principle of least privilege when assigning permissions
Regularly rotate service account keys
Troubleshooting Common dbt™ - BigQuery Issues
You might encounter these typical challenges:
Permission errors: Ensure your service account has necessary roles assigned
Dataset location mismatches: Verify that your dbt™ profile and BigQuery dataset locations align
Quota limits: Monitor your BigQuery usage to avoid hitting API quotas
Wrap Up
By following these guidelines, data teams can create a robust analytics engineering pipeline using dbt™ and BigQuery. This combination allows for efficient data transformation, testing, and documentation, ultimately leading to more reliable and actionable insights, while managing costs effectively - especially if you are a Paradime user 😉
Paradime's got your back for everything dbt™ and BigQuery. Here's why we're crushing it:
Fixed Pricing, No Surprises and Bye-bye, consumption-based chaos. Hello, budget-friendly bliss!
Crystal Clear Costs: What you see is what you get. Period.
AI-Powered Productivity Boost: While others play catch-up, we're already in the future.
How are we doing it?
Turbocharge dbt Development with AI:
Our smart IDE doesn't just code – it thinks with you.Lightning-Fast dbt Pipeline Delivery:
Bolt and CI/CD that'll make your head spin (in a good way).Slash Warehouse Costs, Maximize Efficiency:
Radar Analytics: Your secret weapon for lean, mean data operations.
Ready to leave dbt Cloud™ in the dust? Hit us up for a chat.
Let's skyrocket your analytics game together! 🚀 🙌









