

Introducing Paradime Docs
Introducing Paradime Docs, the AI-driven docs app to write data docs in seconds, with autogeneration, bi-directional YAML sync and cross-platform.

Kaustav Mitra
Jun 13, 2024
·
4
min read
Introduction
Continuing on our journey to Paradime v3.0, we are thrilled to launch Paradime Docs today. It's the only AI-driven docs application that helps write data docs in seconds, not days and months.
Background
It's no secret that there are way too many metadata catalog tools on the market. Most data documentation or catalog tools on the market suffer from two fundamental flaws:
They are not part of the developer workflow - it's another tool you gotta keep updated; it is always a tech debt, and nobody wants to write it.
Data documentation apps eventually become another data silo so the end user is never in control. Once you have used a data catalog long enough, you almost can never get rid of them.
We love dbt™* docs and it solved a big problem by allowing writing documentation in git-tracked yaml files. When I first used dbt™* docs, it was magical. But over time, we realized, that the user experience of writing and maintaining documentation over hundreds and thousands of models was pretty bad. It was one of those things, where using something in a small repo e.g. jaffle-shop was not the same as in a real production use-case. In short, dbt™* docs is a great primitive, but the user experience falls way short for production projects. Pretty much every data leader we have spoken to said, wish they documented more, but it's hard for them to prioritize with ongoing fires.
What's the point of having documentation tools if the writing experience is poor and nobody is going to write? 🤯
Thus, we built Paradime Docs to make writing data docs painless.
How it works
A. Development vs Production
In Paradime Docs, we have a concept of development and production mode.
In development mode, you can add / edit docs from the UI and those will are reflected in your branch as shown below. You can change your branch by navigating to the Code IDE. Only users on the admin and developer licenses can edit while business users have read-only access. There is no limit on the read-only seats.

B. Autogeneration using OpenAI
Nobody like writing documentation, yet everyone needs it. As the dbt™* repository grows, documentation becomes a tech debt. So we wanted to make writing documentation a one-click experience! With the Autogenerate with AI ✨ button, you can
Create documentation explaining your dbt™* model in seconds
Not happy the first time around, you can regenerate
And finally edit before you hit save
Now you can crush your documentation coverage KPIs / OKRs without breaking a sweat 😆.
C. Editing experience: UI -> Code -> UI
Docs has bi-directional sync between the UI and the code in your YAML files. Changes to your docs are instantly available in real-time without having to run dbt™* docs anymore, thus improving development velocity by orders of magnitude.
Regarding editing:
You can edit your YAML file in Code IDE and the changes would show in the Docs UI
You can add/edit your data assets in the Docs UI and we will propagate those changes to the underlying YAML file so your docs is git-tracked and version controlled and stays in your repository
If a column does not exist, we will add it for you in the YAML at the right place when you add a column description in the UI
If a model does not exist, we will add it for you in the YAML at the right place when you add a model description in the UI
If no documentation exists, then we will add a default schema.yaml file in the folder where your dbt™* model exists
We support renaming, re-arranging or moving the YAML files anywhere in the repo
We support docs macros as well - so if you already have macros, and you edit in the UI, we will propagate the change to the correct macro
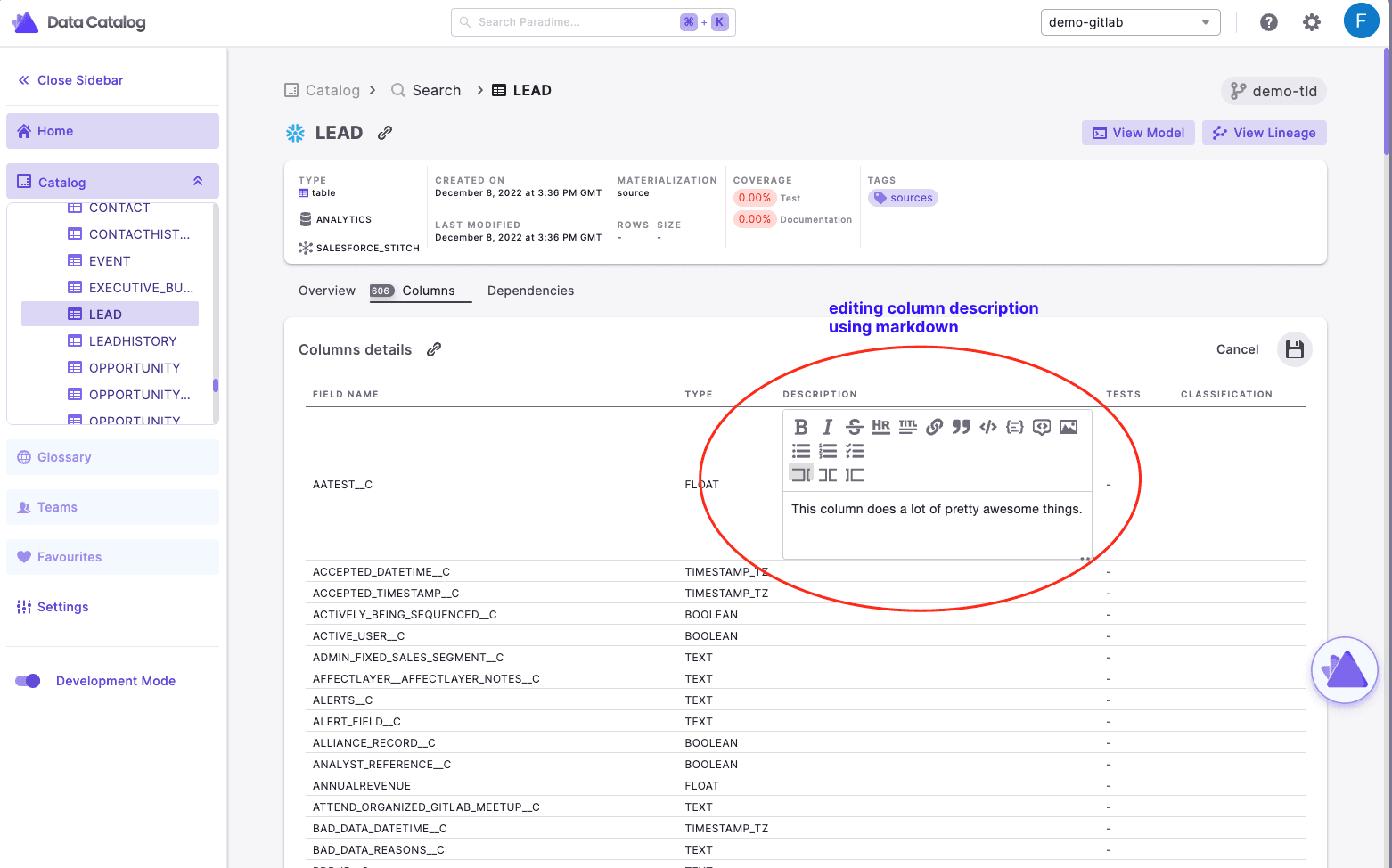
We support adding and editing from the UI:
table descriptions
column descriptions
classification tags at table and column level
When you want to edit, we provide a markdown editor where you can preview your changes before you save anything.
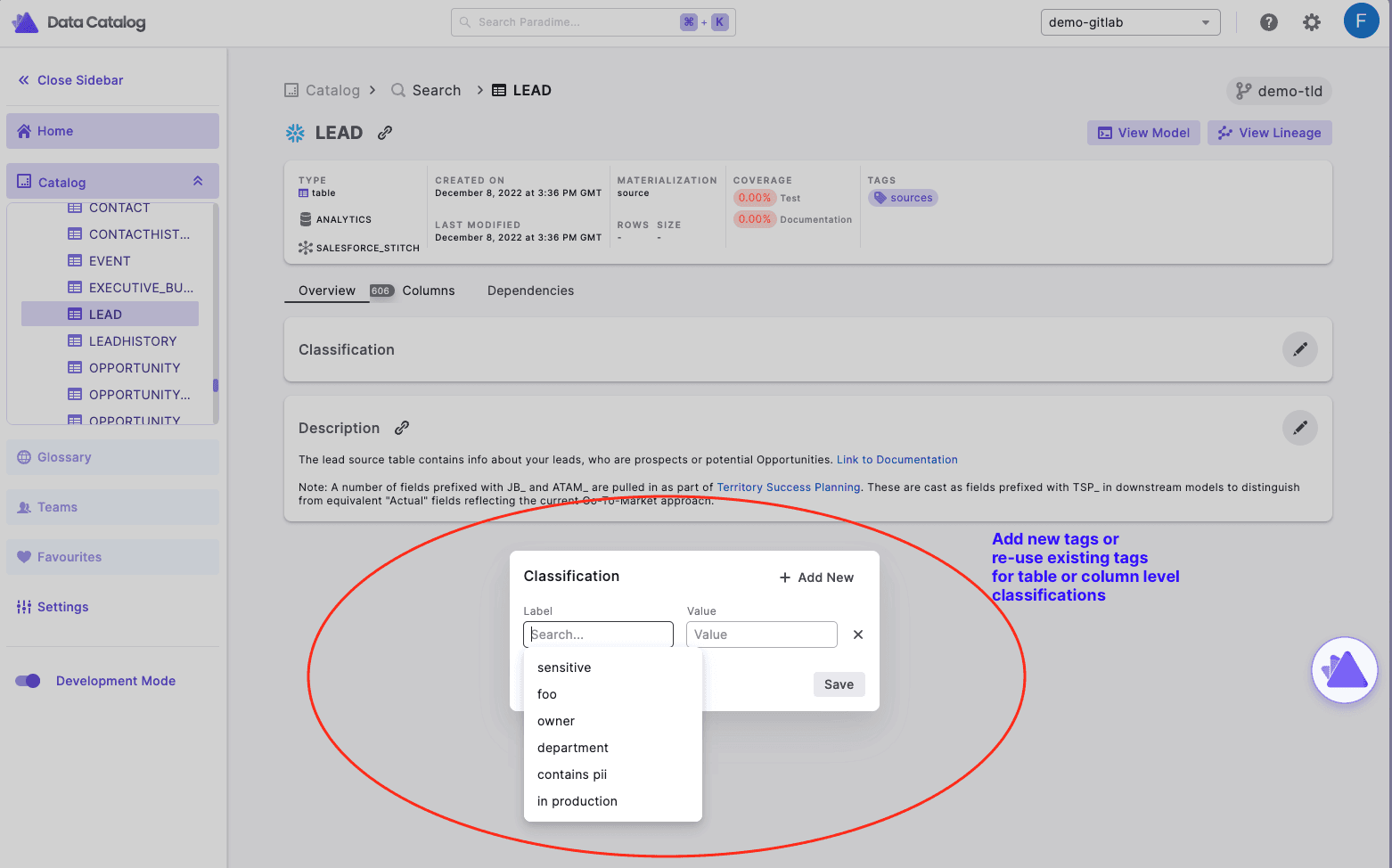
Classification allows us to categorize data assets and dbt Labs™* has done it pretty cool by exposing the meta tags. In Paradime Docs:
we make all your meta tags in your repo automatically available as filters
you can add / delete / update these tags for any data product i.e. tables or columns
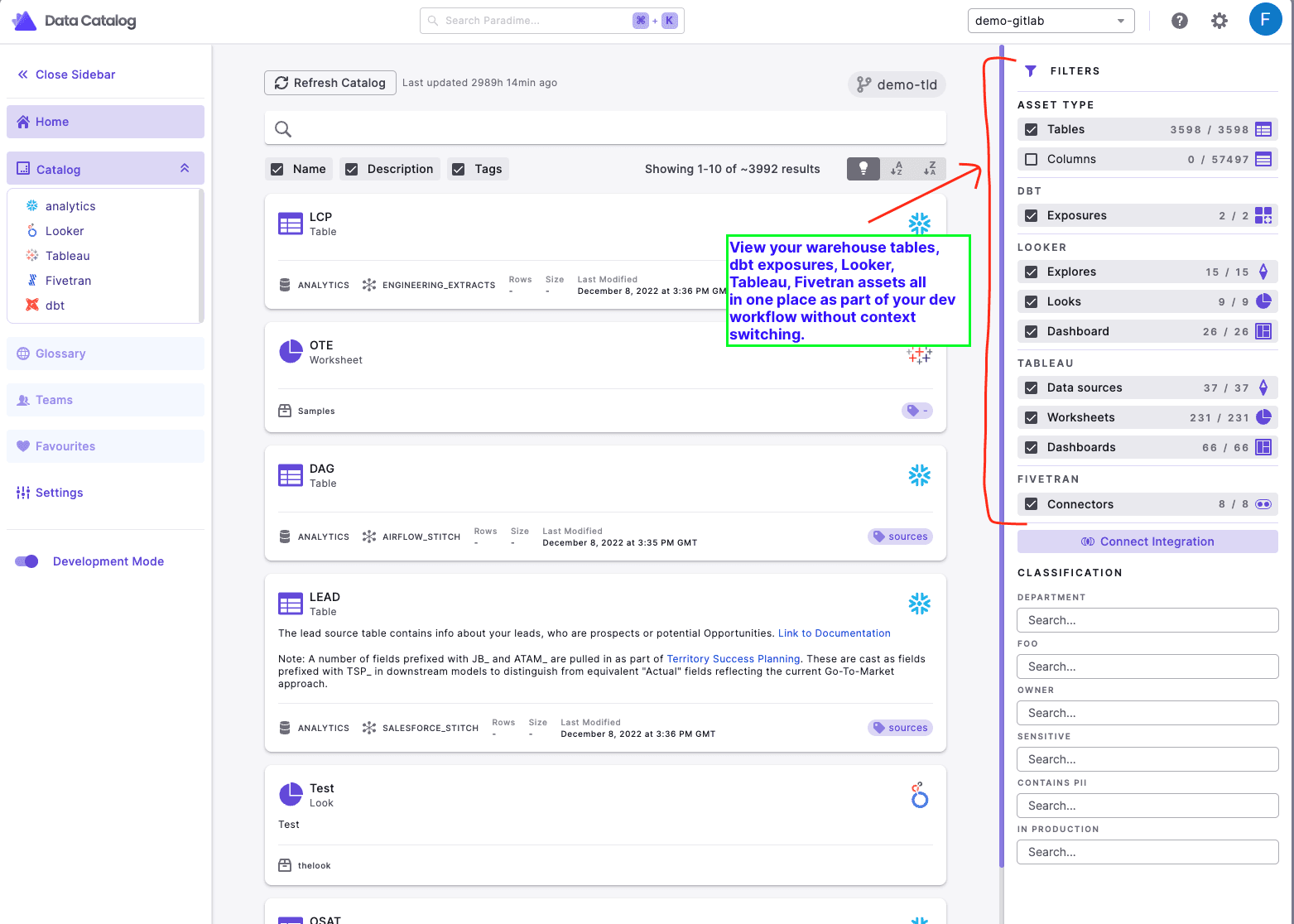
D. Cross-platform
The Paradime Docs is cross-platform. Users can also view their non-dbt data products from Looker, Tableau and Fivetran and more integrations are coming up in the future. With everything in one place, analytics teams can have a consolidated view of their data products when they are making changes.
E. Settings
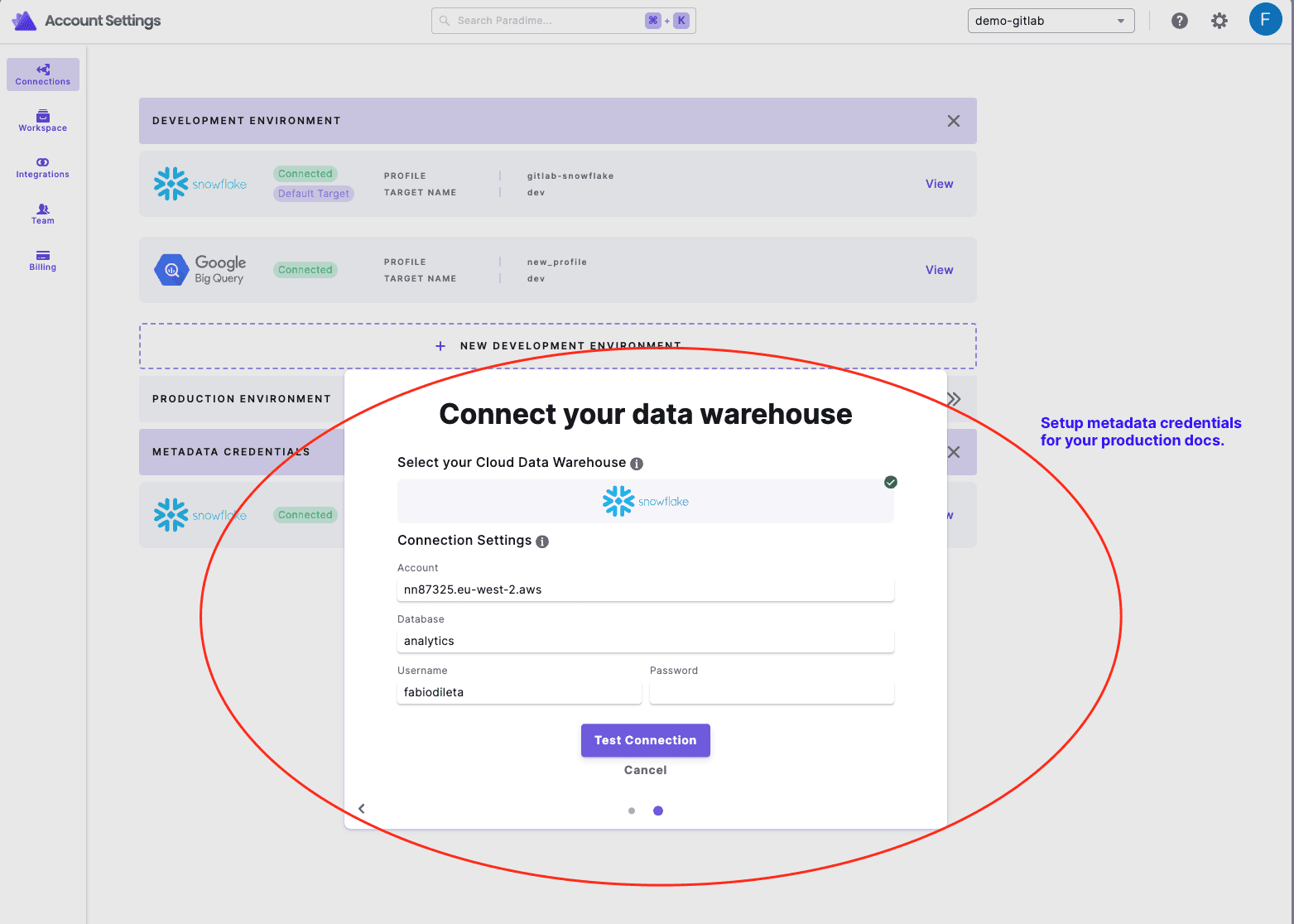
There are a few simple steps to setup the Paradime Docs as follows:
Metadata connection: We need this to inspect the information schema so we can infer the tables and columns in your production docs. More available in our documentation on how to setup for various warehouses.
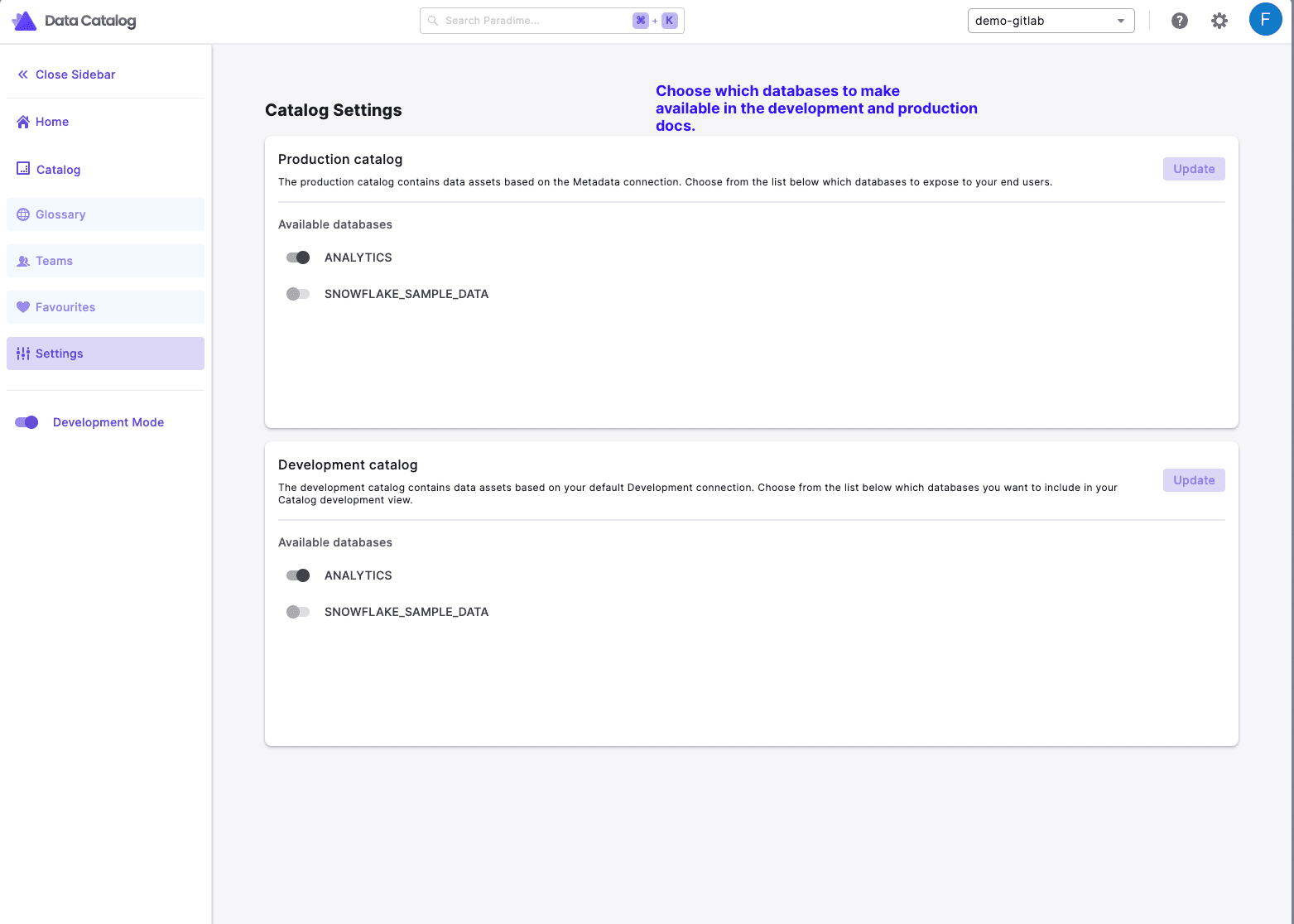
Docs settings: Here admins can choose which databases they would like to expose in the development or production docs.
F. Integrating with your existing Data Catalog
Does this mean as a Data Leader, you will have to throw away your existing Metadata / Data catalog tooling? The short answer is - absolutely no.
You have invested a lot of time in rolling out your metadata solution including onboarding, employee training and many other things. We think with Paradime Docs, you will have a much higher ROI on those investments because your analytics team won't have to deal with documentation debt.
We have built Paradime Docs to remove the friction on writing docs. Because we write back to your repo, the docs are always available in the manifest.json generated at the end of production dbt™* runs. You can continue to point your current metadata apps like Atlan, Select Star and others to where the manifest.json is stored and keep your existing tooling and processes unaffected.
If you don't have an existing data catalog solution, then you can roll out Paradime Docs to your entire organization at no extra cost as read-only seats are free.
What's Next?
We are taking a UI-first approach to data documentation optimized for writing while making sure teams are in control of their data. But we are just getting started here. More cross-platform data assets, a lot more context, and a lot less writing is our dream here.
Our biggest challenge here is to keep the UI clean and data in the UI relevant. And we accept that challenge.
There is a lot more to share about our docs in the coming weeks and months, but this will be an integral part of the connected Paradime experience.
Sign up for a FREE 14-day trial or schedule some time with our team to learn more about Paradime 💪









