

Movie Challenge Rewind: The Franchise Edition
From Star Wars to Harry Potter - here are some of the insights Blosher Brar uncovered.

Blosher Brar
Jun 24, 204
·
4
min read

Hey, I’m Blosher Brar 👋. I’m an analytics engineer and freelance technical writer. Recently, I participated in Paradime’s Movie Data Modeling Challenge, and I'm thrilled to share my experience, insights, and my favorite Paradime features!
Building My Project
My strategy for this project was clear: deeply understand the historical movie datasets, identify potential insights to uncover, and fully utilize the Paradime platform. Inspired by Parker Roger’ blog on successful competition strategies, I began by outlining my ideas on paper.
Next, I defined my end users—movie producers, big Hollywood studios, and movie fanatics—and focused on answering questions around movie franchises, inflation-adjusted box office performance, and ratings.
Lastly, dove into the movie datasets to find valuable patterns for these stakeholders. A major challenge was accounting for inflation, as earnings from the 1970s aren't comparable to today's. To solve this, I integrated historical inflation data, ensuring fair comparisons across different eras.
Here’s the full breakdown of my process:
Data exploration and cleaning: The first step was to explore the datasets and understand their structure. I used Paradime’s data explorer to preview and validate the raw data, which was incredibly useful in identifying any inconsistencies or missing values early on. The intuitive interface allowed me to quickly navigate through large datasets and make necessary adjustments.
Defining the end users: With a clear picture of the data, I defined the primary end users of my analysis. Movie producers would be interested in profitability trends, while movie fanatics would seek insights on high-rated films.
Formulating key questions: I brainstormed a list of questions to guide my analysis:
How do franchise movies compare to non-franchise movies in terms of profitability?
What is the impact of inflation on box office earnings over the years?
How do ratings correlate with profitability for both franchise and non-franchise movies?
Modeling with SQL and dbt™: Using SQL and dbt™ within Paradime, I started building models to answer these questions. With Paradime, I noticed how easy it is to transform raw data into meaningful insights, and I could create staging models to clean and standardize the data, followed by intermediate models to calculate key metrics like inflation-adjusted earnings and average ratings.
Iterative process: Like all data projects, this was an iterative process. As I dug deeper, I discovered new patterns and insights all the time, as well as dead ends. For example, while analyzing franchise profitability, I realized the need to separate out highly successful outliers like the Star Wars series to avoid skewing the results.
Insights uncovered
Check out some of my favorite insights I uncovered, and learn how I built them:
Insight #1: Franchise VS non-franchise profit
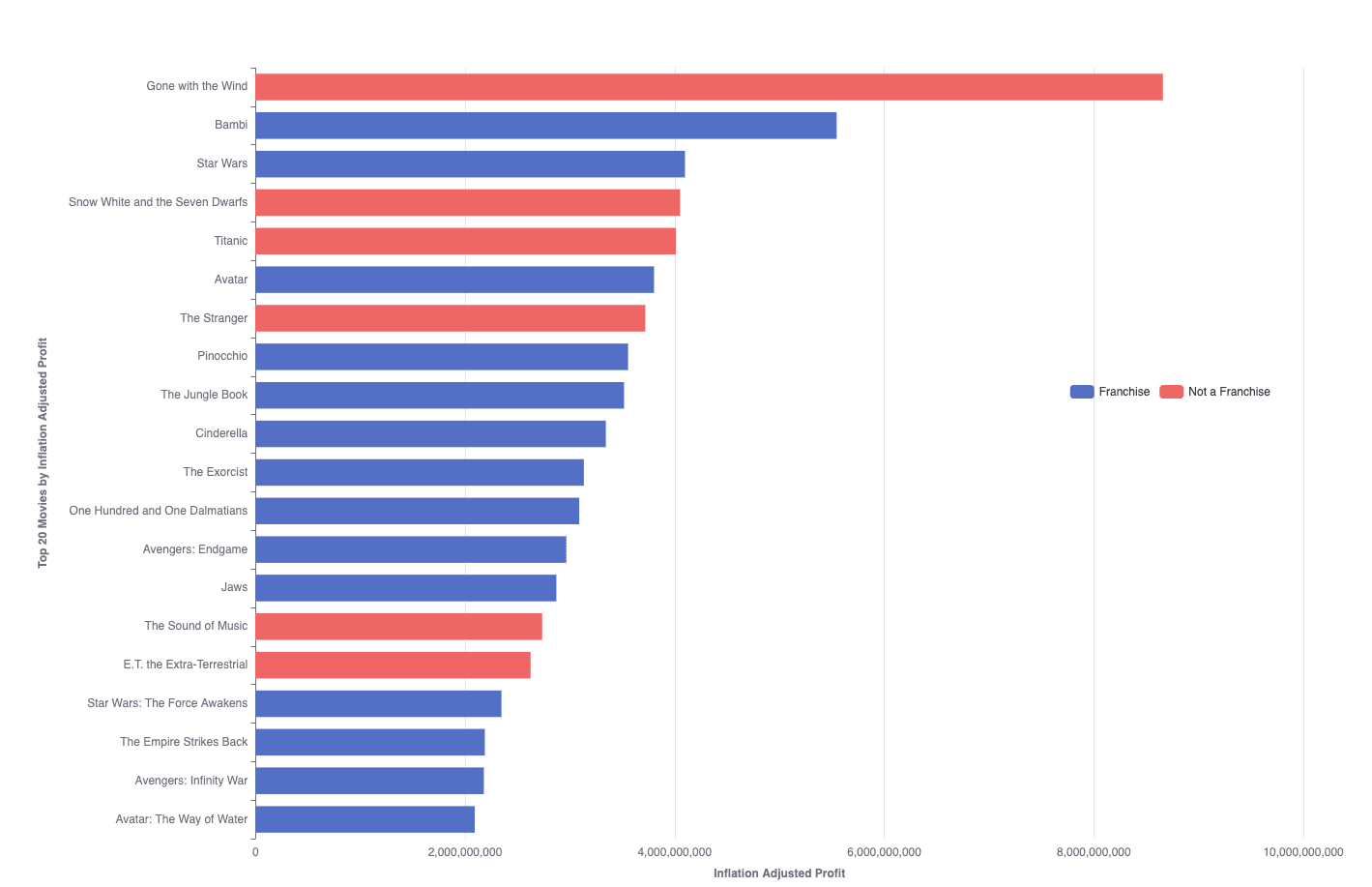
This analysis reveals the profitability gap between franchise and non-franchise movies. Franchises, with their established fan bases and ongoing storylines, consistently outperform standalone films in terms of box office profits. This insight is crucial for movie producers and studios when planning future projects.
Approach:
cleaned_combined_movies.sql: Consolidates, cleans, and enhances movie data from different sources (TMDB and OMDB). It adjusts revenue, budget, and profit figures for inflation using historical inflation factors and identifies movies that are part of a franchise.
sequel_vs_non_sequel_movies.sql: Ranks movies by inflation-adjusted profit in descending order.
Insight #2: Franchise movie profitability & ratings
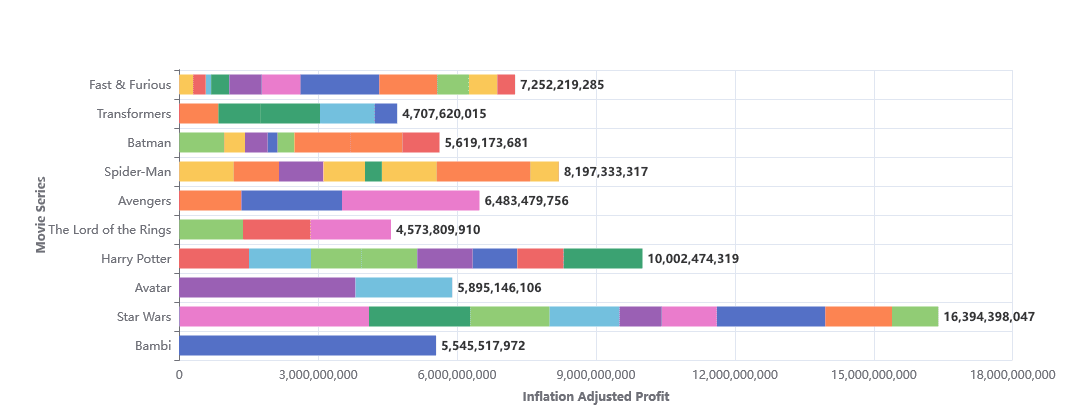
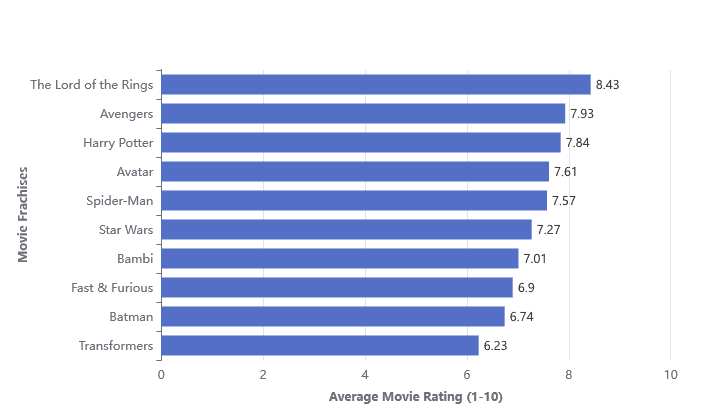
This insight explores the correlation between movie ratings and profitability for franchises. Some high-grossing franchises had mediocre ratings, indicating that established brands can drive box office success despite critical reception. This is crucial for studios balancing creative storytelling with financial returns.
Approach:
clean_combined_movies.sql - Consolidates, cleans, and enhances movie data from different sources (TMDB and OMDB). Adjusts revenue, budget, and profit figures for inflation using historical inflation factors, ratings, and identifies movies that are part of a franchise.
movie_cumulative_sums.sql - Filters out non-franchise films from clean_combined_movies.sql and aggregates remaining franchise films by cumulative profitability and rating, creating a foundational dataset of cumulative metrics for movies within series.
dim_movie_sequel_stats.sql - Identifies the top 10 most profitable movie series from movie_cumulative_sums.sql, calculates their average ratings, and joins this summary with detailed cumulative metrics, offering a comprehensive view of each series and their movies.
Insight #3: Star Wars & Harry Potter comparison
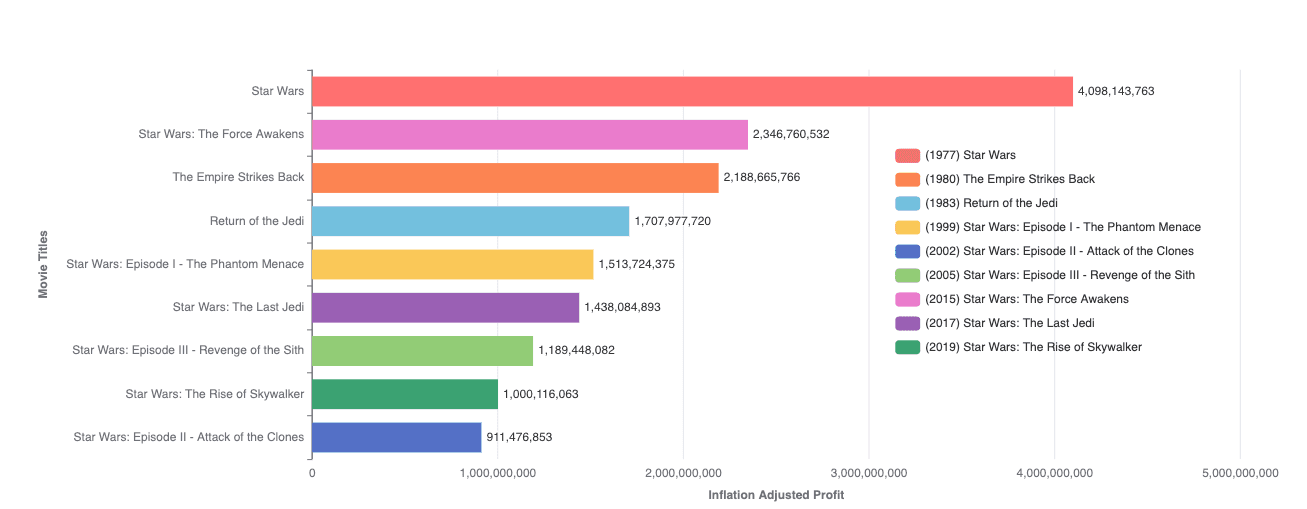
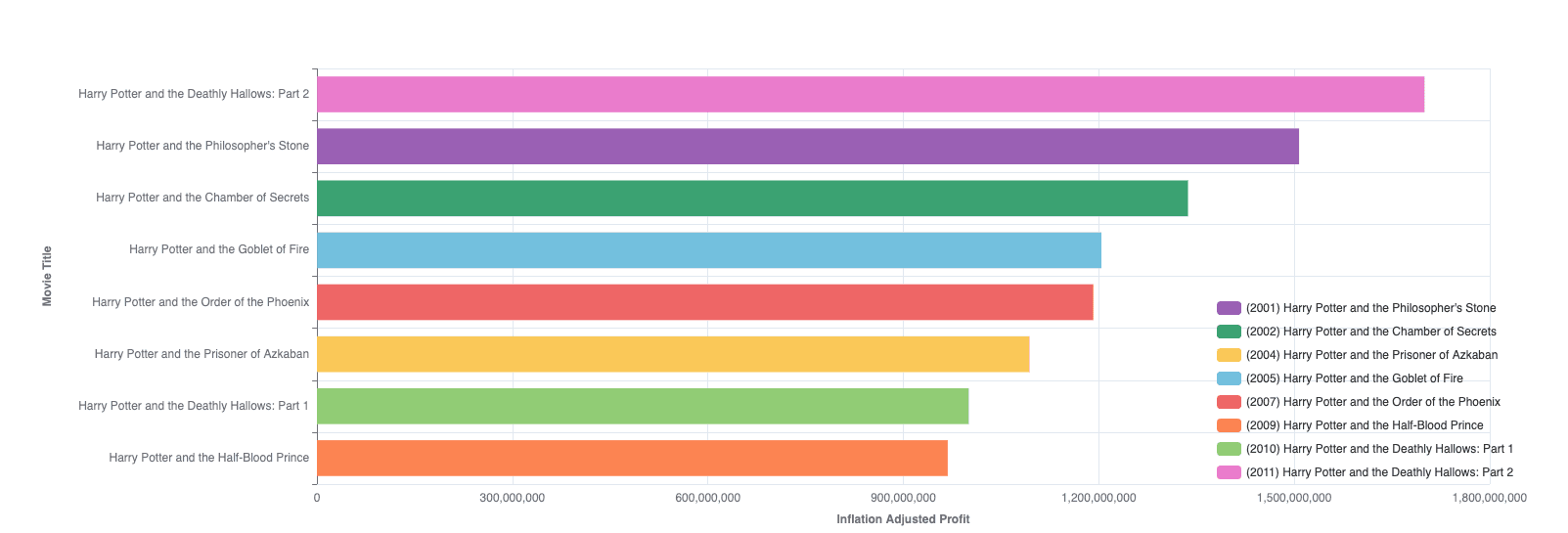
Comparing Star Wars and Harry Potter franchises revealed some interesting trends. While Star Wars’ original movies were immensely profitable, the profitability declined with newer releases. Conversely, Harry Potter’s later movies showed increasing profitability, reflecting growing fan engagement and market expansion over time.
Approach: using the same approach as “Franchise movie profitability & ratings”, I filtered out all movies besides Harry Potter and Star Wars.
My Paradime Stand-Outs
Paradime was a game-changer for how I do my data modeling. Here are some of my favorite features that helped me streamline my workflow and uncover insights faster.
Data Explorer: This feature was a game-changer for me. It allowed me to quickly preview data transformations and ensure everything was working as expected. Just selecting a CTE and getting an instant preview saved me countless hours of debugging and validation.
Integrated Terminal (CLI): One of my favorite features was the predictive suggestions in the terminal. When writing repetitive code, Paradime's DinoAI suggestions sped up my workflow. Instead of typing out commands or copy-pasting, the terminal predicted and filled in the commands for me. This was particularly useful when building data marts, for example.
Development efficiency: Paradime’s intuitive interface and efficient tools allowed me to focus more on analysis rather than getting bogged down by tedious tasks. Paradime truly made my workflow more productive and enjoyable. Give it a try, and you’ll see why I’m have become such a fan
“Developing on Paradime was actually really refreshing. It made the whole process WAY faster and less cumbersome.”
Wrap Up
Participating in this challenge definitely worth my time and energy. Diving into movie franchises and seeing the profitability and ratings trends was super interesting, and it helped me improve my analytics engineering capabilities.
I highly recommend signing up for Paradime’s next dbt data modeling challenge.









