

Slashing analytics development cost with our new DuckDB and MotherDuck integration
Discover how Paradime's integration with MotherDuck and DuckDB unlocks new use cases for analytics teams - with zero cloud compute costs.

Kaustav Mitra
Jul 16, 2024
·
7
min read
Introduction
Last week, we announced that Paradime has partnered up with MotherDuck to help analytics teams adopt DuckDB with ease. We are now the only dbt™ native Code IDE on the market supporting MotherDuck and the DuckDB toolchain 'out-of-the-box'.
At Paradime, we want to bring the best analytics development experience to the market while slashing analytics development costs. Adding support for DuckDB and MotherDuck will enable analytics engineers to reduce their development costs and add a lot more flexibility to their workflow. You can now achieve faster with less friction what would otherwise take weeks (or even months) to get right.
With this new team-up, we are unlocking a few new use-cases in the cloud:
Single-file OLAP databases available in a cloud environment (or cloud VM)
First time ever analytics teams can cut out cloud warehouse compute costs during development within a cloud environment
Terminal UIs in the Cloud — (if you are reading this post and you have a cool terminal UI idea or project, hit us up and let’s work together)
Toolchain for teams on Postgres without a cloud data warehouse to perform analytics
Toolchain to perform analytics on data stored in JSON, Parquet, Iceberg, and other formats in S3 or other Lake type storage
🚀 Analytics work without cloud compute is now possible with Paradime 🚀
Quick intro on DuckDB → MotherDuck
DuckDB is a single-file OLAP database for performing analytics calculations in the file-system without incurring cloud warehouse costs. DuckDB allows loading data from a CSV, Direct Parquet, JSON, or any supported file-system into a DuckDB instance and performing all the querying and analysis on that data.
Other uses of DuckDB include:
embedding within a browser-based application using duckdb-wasm
use embedded DuckDB instances to read and perform “light” data transformation during ingestion into a cloud data warehouse (source: LinkedIn post)
But there is one critical limitation of DuckDB for analytics development — it’s single-player, i.e. each DuckDB user can only work on their own local machine, and their work cannot be shared easily with other users.
MotherDuck enables those isolated DuckDBs across local machines to become part of a collaborative, serverless, and production-ready analytics platform. This new pattern of execution means teams can get work done:
with limited data sets for analytics extracted into files like CSV, Parquet, JSON, Iceberg, etc. without loading them into a cloud warehouse and therefore not having to scan huge tables.
without a cloud data warehouse, which means teams using Postgres can now load up data into MotherDuck and then access them locally on their machines for analytics.
with raw data within their local machines (running queries, dbt™ models and creating new datasets) and when ready, push that data back to MotherDuck from within the DuckDB CLI.
Here comes the Paradime shift
Getting started with DuckDB today requires teams to build their toolchain from scratch, which adds friction. They would also have to maintain this infrastructure over time. In short, it's time consuming and not the easiest thing to maintain. This is where Paradime comes in.
Paradime is the dbt™ native workspace for analytics teams - one could say it’s like Google Workspace but for analytics work. Within Paradime Code IDE, analytics teams get their data work done at high velocity and without context switching.
With the Paradime MotherDuck integration, we are erasing complex infrastructure with the goal of providing end-users with an end-to-end platform for MotherDuck and DuckDB development.
What’s included?
1. MotherDuck integration - power collaborative and serverless analytics. Paradime now has native support for MotherDuck, and their users will now be able to
setup their DuckDB in Paradime,
do all their dbt™ development on top of local DuckDB, and
push their local DuckDB to MotherDuck.
2. dbt-duckdb - build and run dbt™ models. The dbt-duckdb adapter gives analytics engineers superpowers to build and run dbt™ models against their local DuckDB and push new datasets to MotherDuck. If you are on Postgres and don’t want to invest in a cloud data warehouse just yet, this is the solution for you. If you have most of your data in S3 buckets, and not ingested in your warehouse, you can use Paradime, MotherDuck, and dbt-duckdb to build your analytics stack on local compute.
3. DuckDB CLI. The DuckDB CLI is included in the terminal environment. Users can perform analytics queries on CSV, Iceberg, Parquet, JSON, and other formats from the terminal. Using any of the supported DuckDB extensions, users can create local DuckDBs and write SQL queries.
4. Harlequin IDE - a fully functional query IDE in the Paradime terminal. To facilitate SQL querying, the powerful Harlequin SQL IDE is also included. Now, you can open any local DuckDB file in Harlequin inside a Paradime terminal and get the full power of the terminal UI on the cloud. Using terminal UIs in the cloud makes the terminal experience 100x better (if we might say so ourselves) and accessible for anyone to get started.
5. DuckDB extensions — use any supported DuckDB extension. Every supported DuckDB extension is available to use. You see, here at Paradime, we are not big fans of constraints and limitations - and neither are our users.
Use cases
We are starting to see new use cases and access patterns emerging, where analytics workloads will not be purely cloud warehouse-focused but a hybrid of cloud and single-file OLAP. Any analytics work can be broken down into two distinct steps. 1) the development / exploratory phase and 2) the production / operational phase. We also predict that the development / exploratory phase will move from a cloud warehouse to DuckDB.
Analytics on file-based data
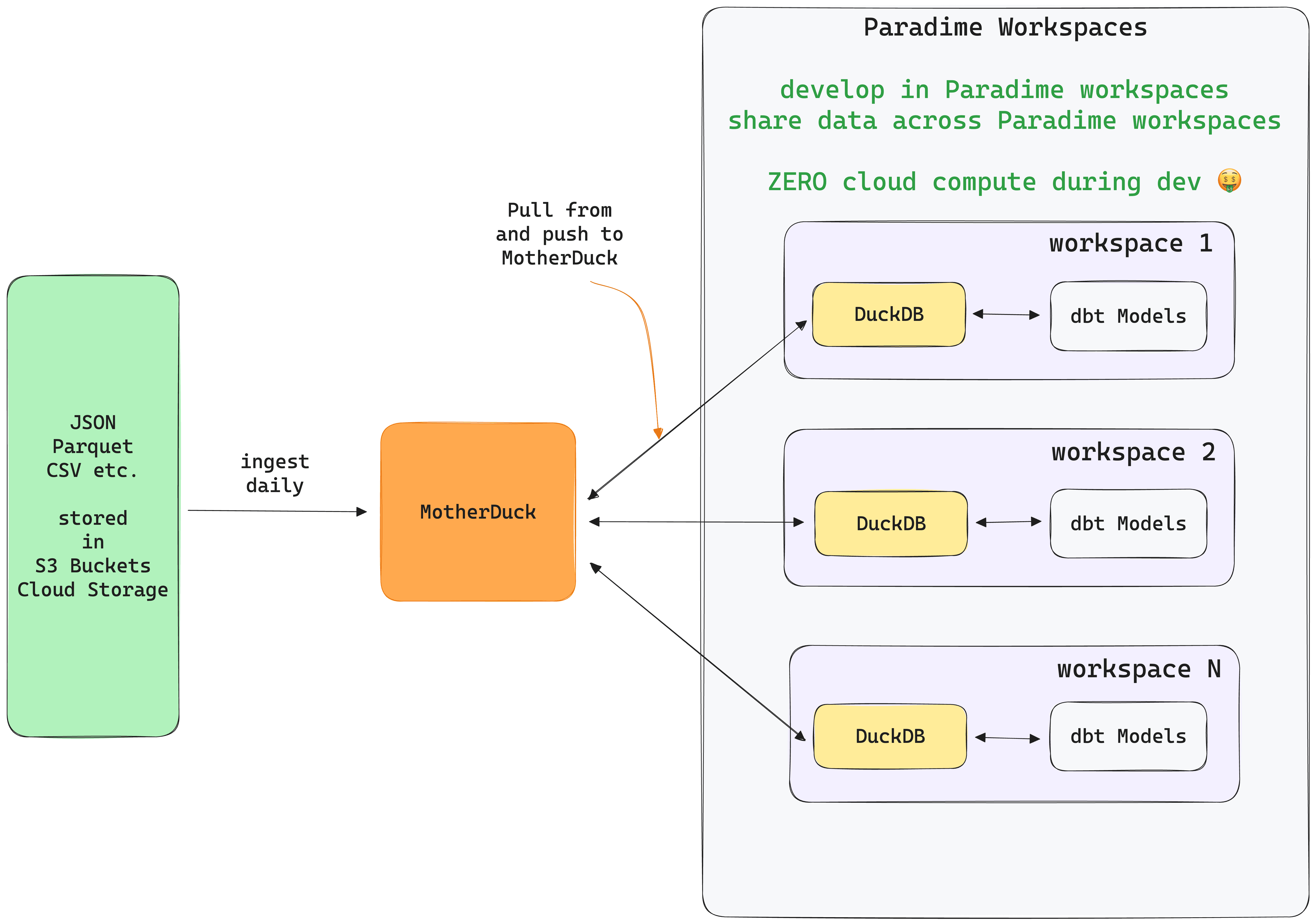
Many organizations' data is stored in S3, parquet, or JSON files - like logs, events, device data, etc. They are stored in huge numbers in a file system, but only a subset is useful or needed for analysis.
In a scenario like this, a team can implement a pipeline that continuously refreshes the dataset and writes last x days of data to MotherDuck. That dataset is available within every connected DuckDB instance within each Paradime workspace or local machine.
Analytics engineers in each Paradime workspace or local machine always have access to fresh data, and they can then build their dbt™ models against this limited data set without spending any cloud compute.
Analytics without a cloud warehouse
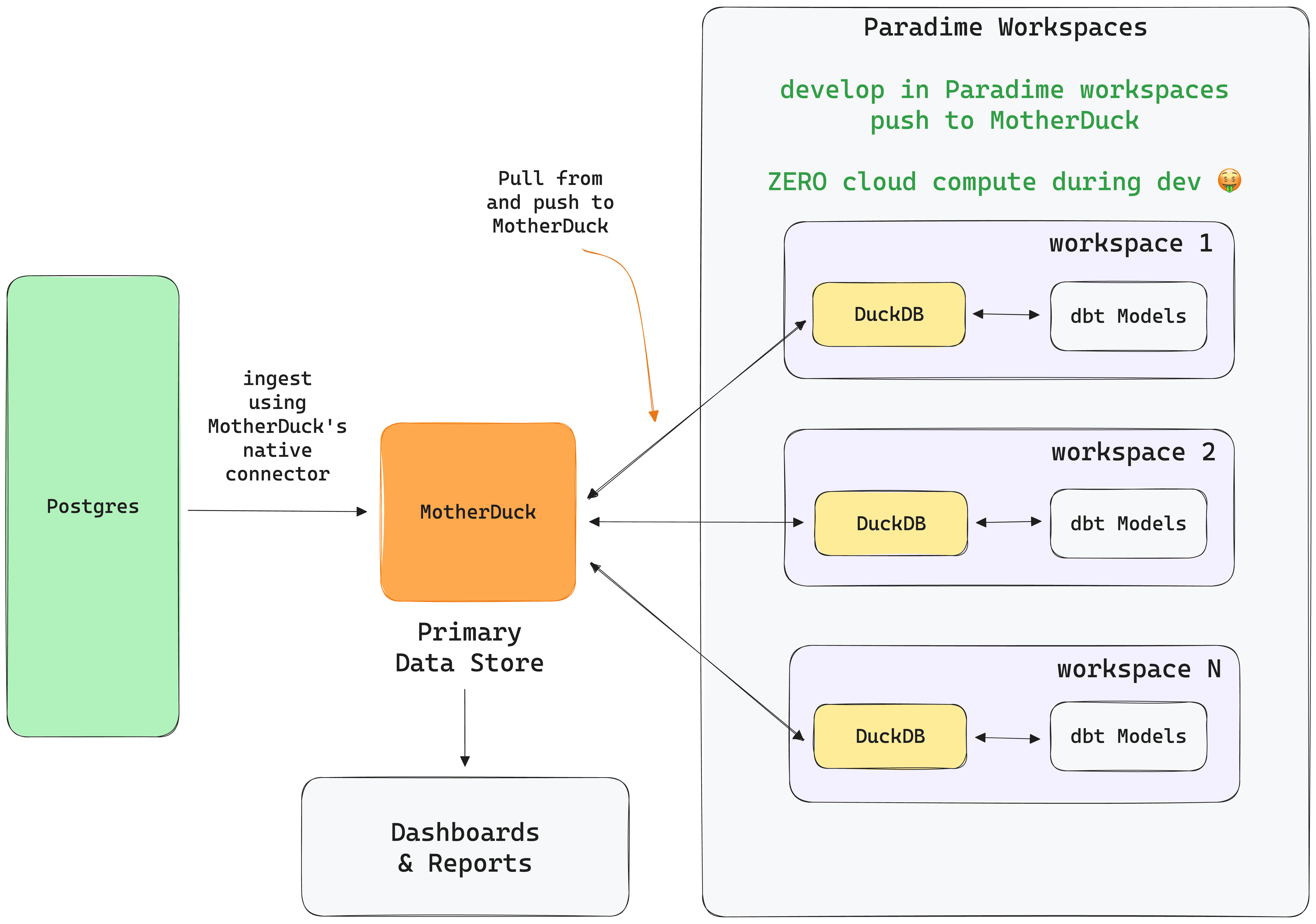
An organization may not have a cloud warehouse or has yet to reach that maturity to need or invest in one. In such a scenario, teams can ingest their data from Postgres into MotherDuck and share it across isolated DuckDB instances in each Paradime workspace.
Once the data is available in DuckDB from MotherDuck, users can query, build dbt™ models and analyze their data in their Paradime workspace without spending any cloud compute. When ready, users can then push their analyzed datasets back to MotherDuck. These datasets would be available across the organization in dashboards for consumption and Paradime instances for development.
In this scenario, MotherDuck acts as a primary data store and individual DuckDB instances work as temporary data stores.
Analytics on data subsets
Some organizations, like big enterprises, have huge amounts of data and it is not practical to give individuals or teams access to everything in the data warehouse. One example is if you are a hedge fund or run a securities trading business. In this case, it's not best praxis to open up a complete trading database for access. Teams and/or individuals would typically go through multiple approvals to get access to a data extract based on needs and requirements.
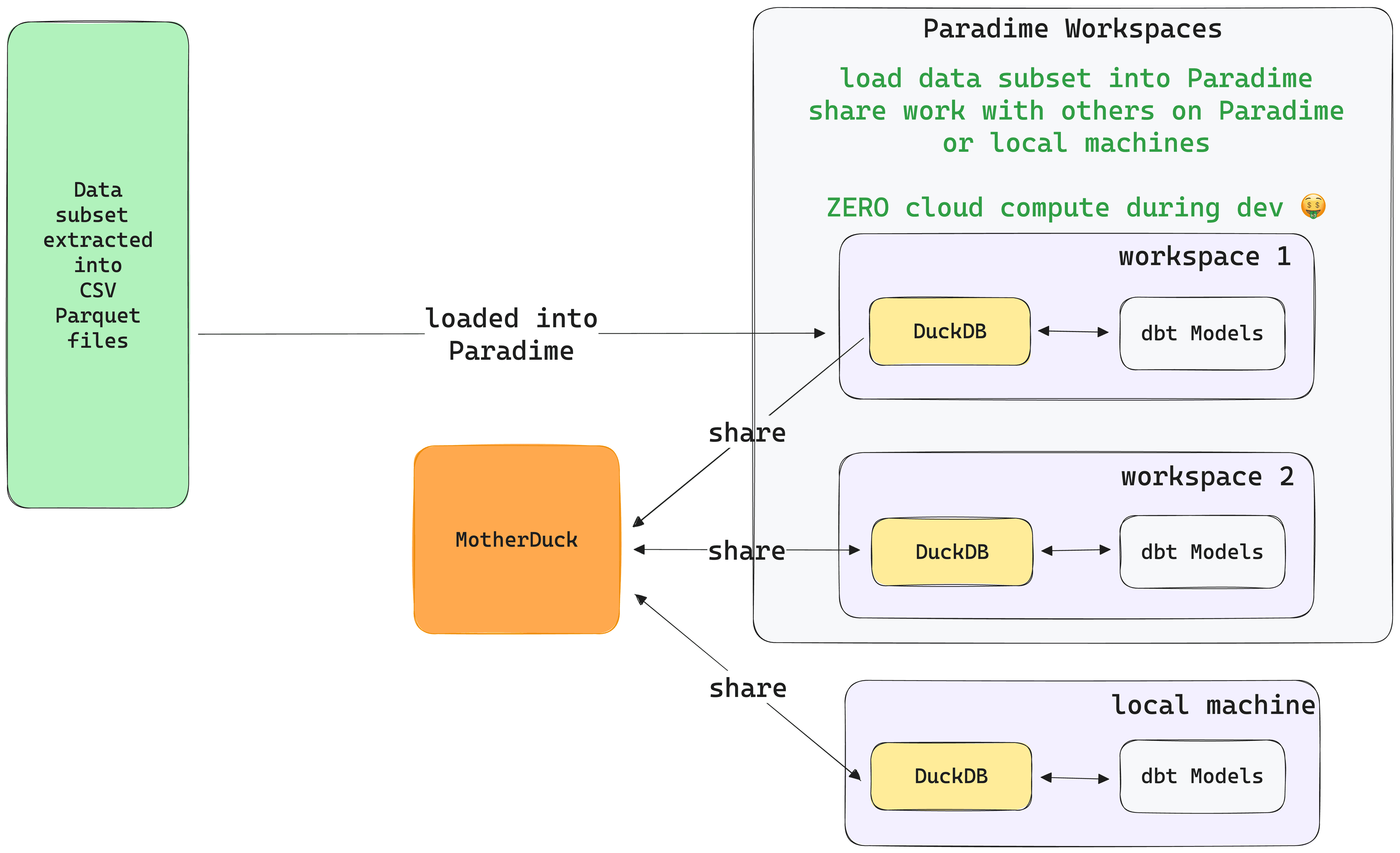
Multi-engine data stack
The last pattern starting to get traction is the concept of a multi-engine data stack. The idea here is that teams would extract data subsets directly into their local DuckDB or through MotherDuck from their current cloud warehouse and then perform all their exploratory data analysis and development work on that subset in their Paradime workspace or local machine. This entire workflow, which really is the bulk of analytics engineering work, would consume zero cloud compute.
Once analytics models are built and tested, you can use a transpiler-like sqlglot to convert DuckDB SQL to the cloud warehouse SQL dialect and then deploy models. These models will go through the regular CI/CD checks; once everything passes, teams can safely deploy changes to production.
In this scenario, your team would have spent zero extra dollars 🤑 during the development work.

This was explored in detail by Julien Hurault in his substack post on multi-engine data stack HERE.
While bringin all these exciting use cases to the table, we are removing the complexity of infrastructure, boilerplate, version management, etc., so that end users can focus on what matters - getting work done. Paradime workspaces provide the toolchain and the flexibility hyper-productive teams need to power their analytics workloads.
Things you can do in Paradime
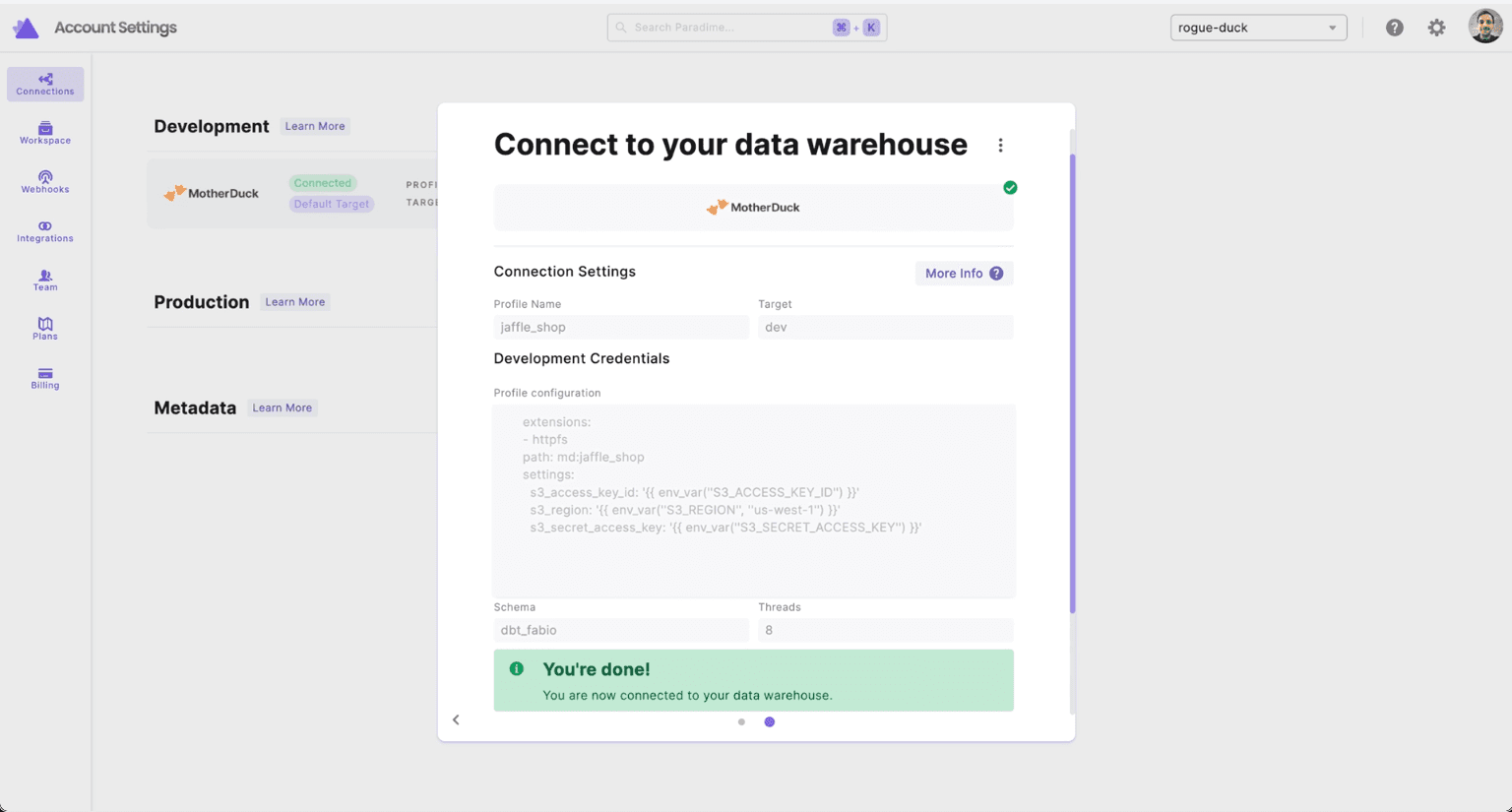
A. Setup MotherDuck/DuckDB connection
Add the motherduck_token environment variable in Personal Settings - Check out Authenticating to MotherDuck to get the service token.
Add the MotherDuck warehouse connection in Account Settings > Connections with any valid dbt™ profile configuration for DuckDB
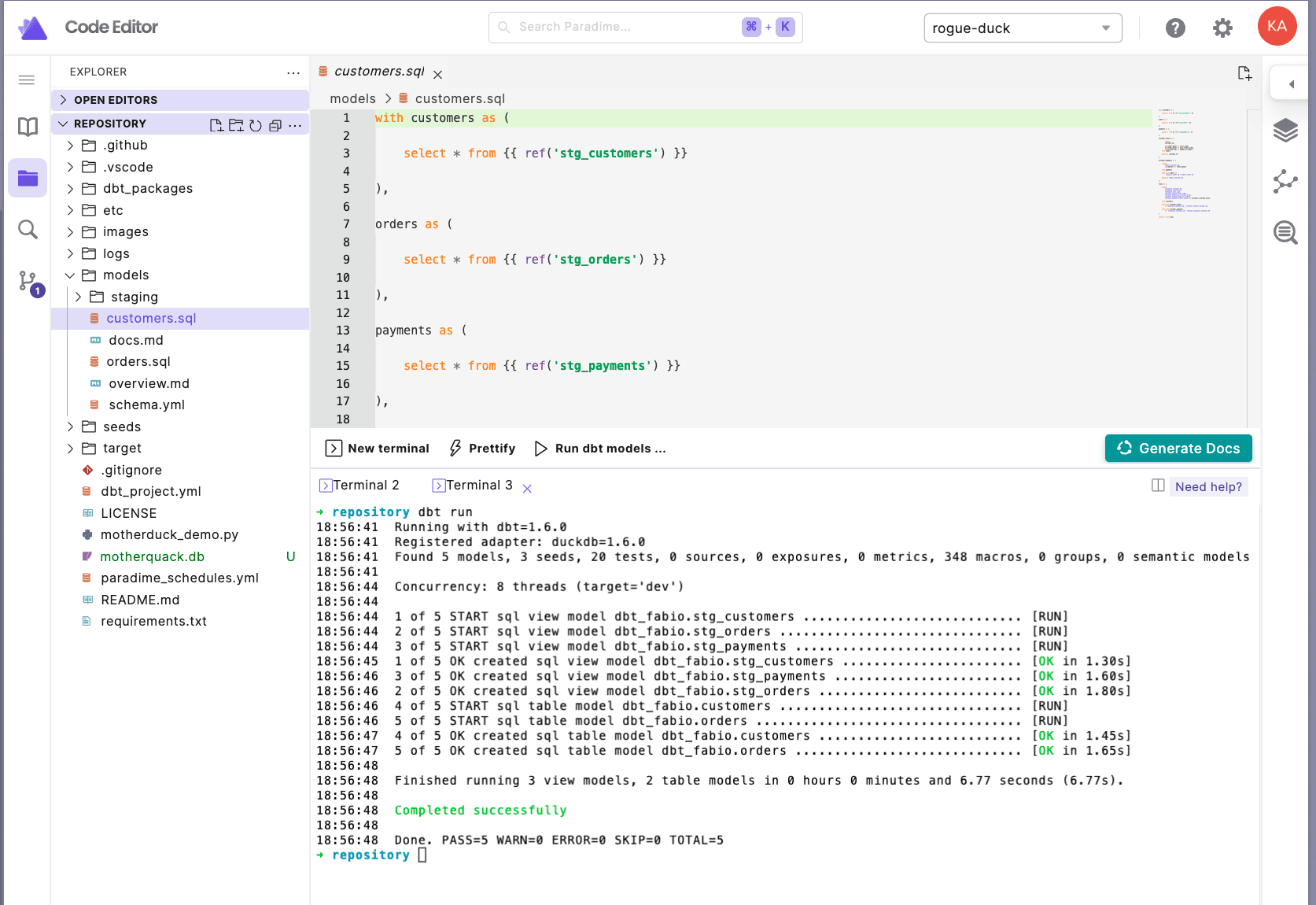
B. Load CSV data into local DuckDB and run dbt™ models on it
Once connected, users can create a local DuckDB, seed it with csv files, run dbt™ models against it, and so on. It's now available in the Paradime Code IDE to kick-start DuckDB development. Want to learn more about our IDE? Book some time with us.
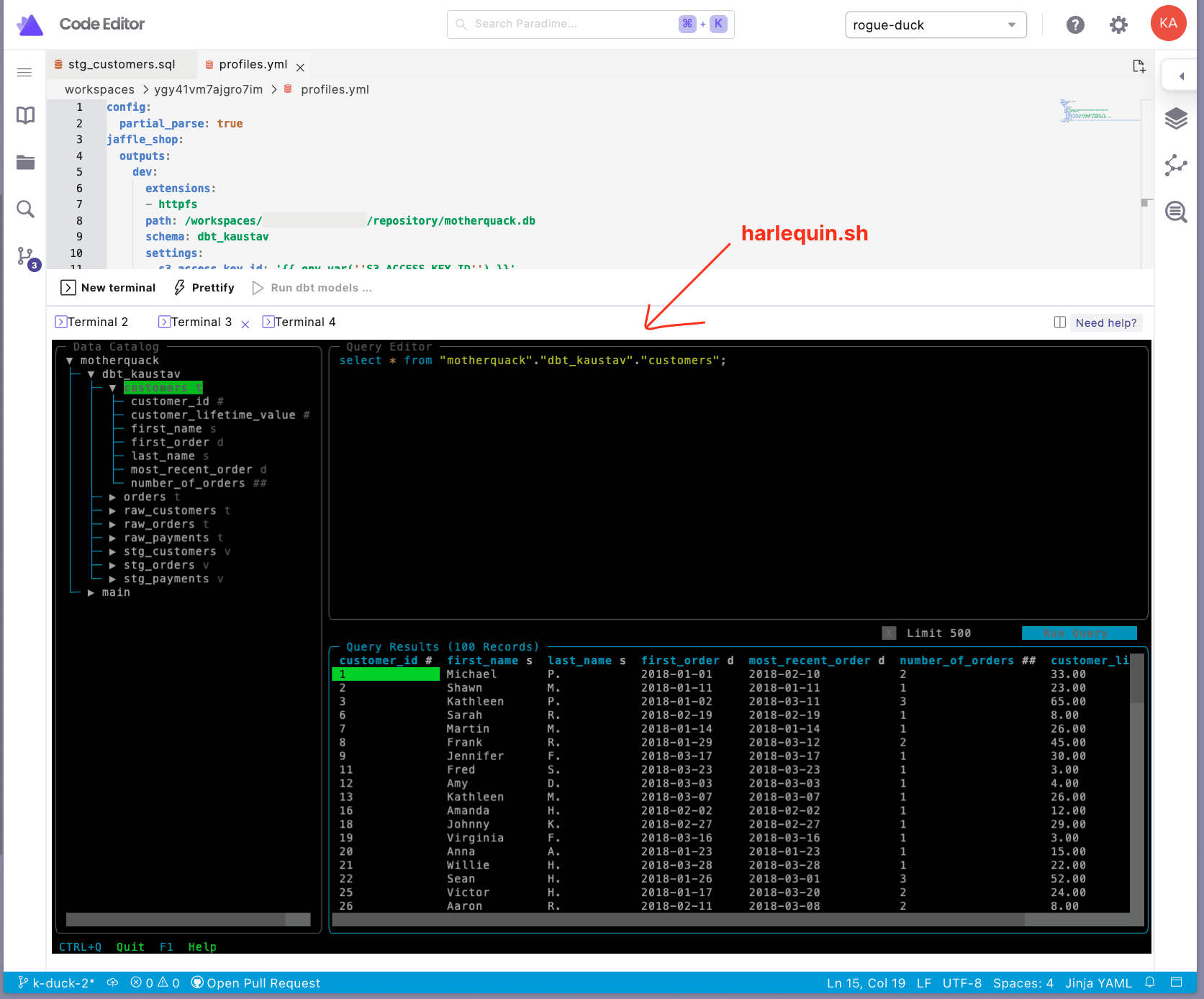
C. Query data using Harlequin
Fire up the Harlequin query IDE in the Paradime Terminal and query, analyze, or use it as a drop-in replacement for the DuckDB CLI. Isn't it pretty epic that Paradime Terminal supports external terminal UIs out of the box? If you are thinking of developing analytics apps as terminal UIs, get in touch, and we can chat about a team-up.
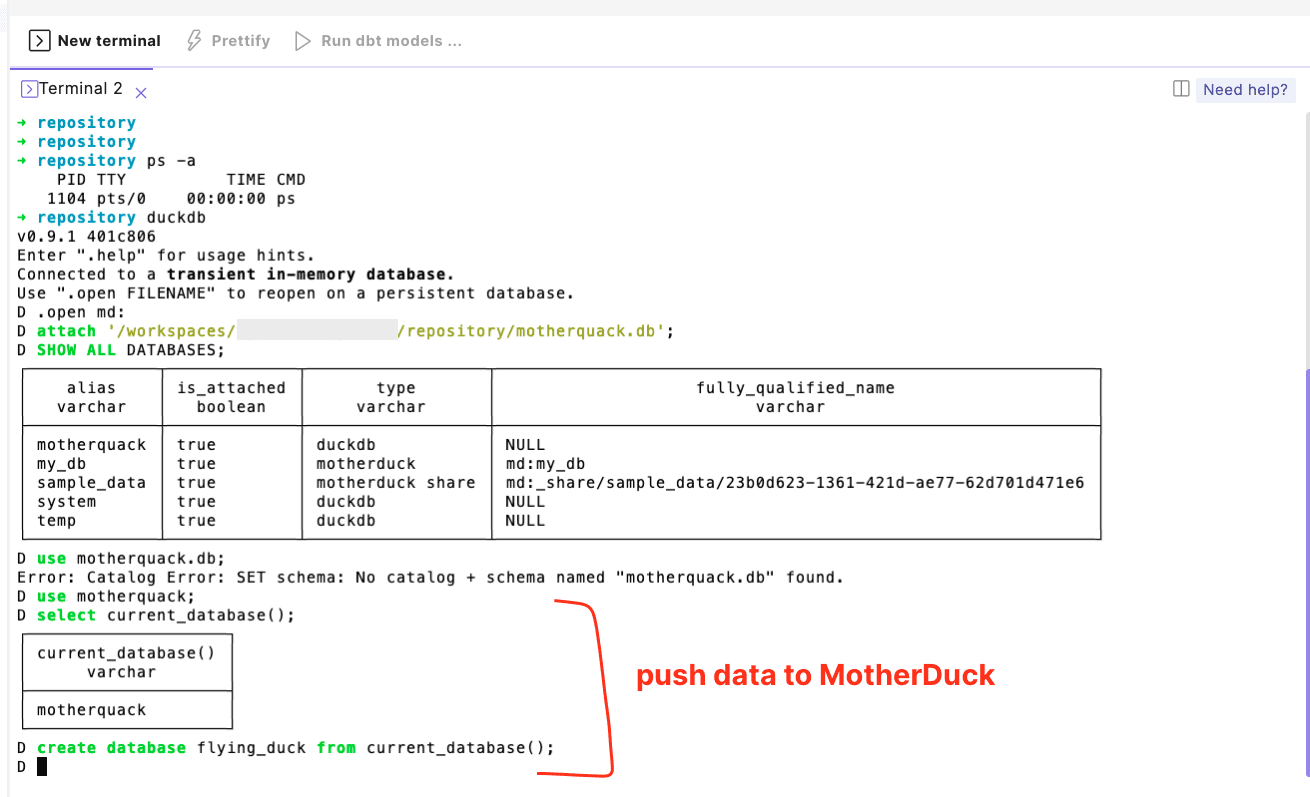
D. Push local DuckDB to MotherDuck
This is the dope part 🔥
So far, anyone working on their local DuckDB would only have access to their own DuckDB. With the MotherDuck integration, you can now open a portal (very Rick & Morty of us) to MotherDuck from within the DuckDB CLI, issue any MotherDuck command, and, in just seconds, make your work shareable through the MotherDuck platform.
All the work within the Paradime workspace now becomes part of a serverless cloud platform accessible to anyone connected to the MotherDuck instance. However, all the analytics work performed within the Paradime workspace would not incur any cloud compute costs.
Conclusion
With the availability of MotherDuck and DuckDB toolchain within Paradime, analytics teams can focus on new ways of working without worrying about infrastructure.
Teams can now:
analyze data where it sits in CSV, Parquet, JSON, and Iceberg files
reduce cloud warehouse costs during development
share datasets across the organization without additional tools
Together with MotherDuck, we have unlocked new levels for data practitioners.
If you are using MotherDuck and/or DuckDB, thinking about it, building OSS tooling, or are keen to partner up - give us a shout. Together, we have the opportunity to build the future of analytics tooling.









